(This post can also be seen here).
The thing that drew me back into theoretical physics was the need to learn Information Field Theory (IFT) for some of my current research on detecting the (very faint) radio emission associated with the large-scale structure of the universe (an older paper on the subject is here). IFT is basically Bayesian statistics applied to fields, but in certain cases the a posteriori probability can be computed through perturbation theory. Feynman diagrams can be used to compute the expansion (below are examples of a few terms), so I was forced to go back to my QFT book to remember the basics of perturbation theory….which led me back to QFT in general…. so here I am.

So what is IFT and why does it look a lot like QFT? I haven’t yet talked about QFT, but I can begin to explain IFT, at least the basics.
Consider a signal 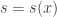 , which is a function of position (a classical field), and we wish to make some inference about this field based on observational data
, which is a function of position (a classical field), and we wish to make some inference about this field based on observational data  . A common inference would be to make an image (map) from incomplete data. We model our measurement process as
. A common inference would be to make an image (map) from incomplete data. We model our measurement process as  , were R is an operator describing the coupling between the data and signal, and n is random noise. Typically
, were R is an operator describing the coupling between the data and signal, and n is random noise. Typically  is continuous and is discrete, so R will be some sort of selection function. It can also include more complicated transformations (e.g., Fourier transformations in the case of radio astronomy). In most cases,
is continuous and is discrete, so R will be some sort of selection function. It can also include more complicated transformations (e.g., Fourier transformations in the case of radio astronomy). In most cases,  is gaussian, but it need not be.
is gaussian, but it need not be.
We don’t know what the actual signal is, so  is really just our model of what we think the signal is. In this case we’d like to compute the a posteriori probability that our model is the correct one given the data, denoted by
is really just our model of what we think the signal is. In this case we’d like to compute the a posteriori probability that our model is the correct one given the data, denoted by  . Bayes’ theorem tells us that
. Bayes’ theorem tells us that

where  is the probability of getting given , called the likelihood,
is the probability of getting given , called the likelihood,  is the prior probability of model , and
is the prior probability of model , and 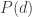 is the evidence, which is the normalization factor given by
is the evidence, which is the normalization factor given by
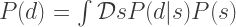 .
.
The integral is a functional integral of the likelihood over all possible configurations of , weighted by the prior probability of that configuration . The likelihood contains information about the measurement process, and is typically a function the model signal’s parameters. There’s a lot out there on Bayes’ theorem so I won’t talk about it here, but is can be derived from basic facts about probabilities and Aristotelian logic.
The step taken in Ensslin et al. (2009) is to rewrite Bayes’ theorem in the form

where ![H[s] \equiv -ln(P(d|s) P(s))](https://s0.wp.com/latex.php?latex=H%5Bs%5D+%5Cequiv+-ln%28P%28d%7Cs%29+P%28s%29%29&bg=ffffff&fg=333333&s=0&c=20201002) is the Hamiltonian, and
is the Hamiltonian, and 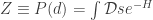 . Things are starting to look suspiciously like statistical mechanics, where
. Things are starting to look suspiciously like statistical mechanics, where 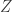 is essentially the partition function; there are more links to stat. mech. that I can get into later. Let’s first consider an example.
is essentially the partition function; there are more links to stat. mech. that I can get into later. Let’s first consider an example.
Imagine that the signal we are trying to observe (make an image of) is a Gaussian random field (e.g., the cosmic microwave background fluctuations) denoted by  . Let’s assume that the value of at
. Let’s assume that the value of at  is not known, but we do know the signal covariance
is not known, but we do know the signal covariance  , i.e., the variance
, i.e., the variance  of the Gaussian field. We can also assume that our observational noise is Gaussian
of the Gaussian field. We can also assume that our observational noise is Gaussian  (it often is), with an unknown value at any point, but with a known covariance
(it often is), with an unknown value at any point, but with a known covariance  . In this case, the likelihood can be written as
. In this case, the likelihood can be written as  and the prior probability is given by
and the prior probability is given by  ….. take a minute to convince yourself of this. In the case of the likelihood, if you assume is true, then the probability that you measure is going to depend on how far away is from , and will be a Gaussian. Explicitly, these are given by
….. take a minute to convince yourself of this. In the case of the likelihood, if you assume is true, then the probability that you measure is going to depend on how far away is from , and will be a Gaussian. Explicitly, these are given by

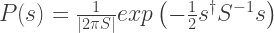 .
.
This is all in matrix notation, where 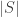 is the determinant of
is the determinant of  . As an exercise one can compute the Hamiltonian
. As an exercise one can compute the Hamiltonian
![H[s]=-ln(P(d|s)P(s))=\frac{1}{2}s^{\dagger}D^{-1}s - j^{\dagger}s + H_{0}](https://s0.wp.com/latex.php?latex=H%5Bs%5D%3D-ln%28P%28d%7Cs%29P%28s%29%29%3D%5Cfrac%7B1%7D%7B2%7Ds%5E%7B%5Cdagger%7DD%5E%7B-1%7Ds+-+j%5E%7B%5Cdagger%7Ds+%2B+H_%7B0%7D+&bg=ffffff&fg=333333&s=2&c=20201002) ,
,
where
![D= [S^{-1} + R^{\dagger}N^{-1}R]^{-1}](https://s0.wp.com/latex.php?latex=D%3D+%5BS%5E%7B-1%7D+%2B+R%5E%7B%5Cdagger%7DN%5E%7B-1%7DR%5D%5E%7B-1%7D+&bg=ffffff&fg=333333&s=2&c=20201002)
is called the propagator of the free theory, and the information source  is given by
is given by
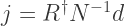 .
.
The constant 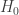 is the collection of all the terms independent of , is is given by
is the collection of all the terms independent of , is is given by
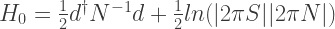 .
.
To compute , one just needs to plug in this Hamiltonian into Bayes’ theorem and compute the partition function integral. To obtain what we originally wanted, which was a map  of the signal , we simply need to compute the expectation value of with respect to , or
of the signal , we simply need to compute the expectation value of with respect to , or
 .
.
This integral can be calculated in a number of ways. One way in particular is particularly useful for the perturbative extension of the theory, but for now one can compute directly that  . In the continuous limit this reads
. In the continuous limit this reads
 , and is represented by the diagram x
, and is represented by the diagram x  y, where the external coordinate with no vertex is , the vertex coordinate is
y, where the external coordinate with no vertex is , the vertex coordinate is  , and the line connecting them represents the propagator
, and the line connecting them represents the propagator 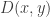 . The vertex represents the information source
. The vertex represents the information source  , and we should sum/integrate over the vertex (called internal later) coordinate. The intuitive understanding here is that contains all the data (projected onto the continuous space of the model, weighted by the noise via
, and we should sum/integrate over the vertex (called internal later) coordinate. The intuitive understanding here is that contains all the data (projected onto the continuous space of the model, weighted by the noise via  ), and will “propagate” this information (it knows about the prior source covariance ) into unobserved parts of the map .
), and will “propagate” this information (it knows about the prior source covariance ) into unobserved parts of the map .
All of this was already well understood in image reconstruction theory (in the form of a Wiener filter), but with the formalism of IFT, we can next look at what happens if we have higher order perturbations to the free theory Hamiltonian (and one often does!). Look for part II in the coming weeks.


Shea,
I’d like to know more about the measure in those integrals, the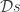 . I’m woefully ignorant of measures in statistical mechanics but I suspect much of the rigorous treatment lies therein. On a barely related note, are you familiar with the “Riemann Gas” where by the particles are prime numbers and the partition function is the Riemann Zeta function?
. I’m woefully ignorant of measures in statistical mechanics but I suspect much of the rigorous treatment lies therein. On a barely related note, are you familiar with the “Riemann Gas” where by the particles are prime numbers and the partition function is the Riemann Zeta function?
Oh, nevermind…looks like I have some reading to do, I missed the comment on functional integration.